zhaosf:原理、应用与未来展望
zhaosf:原理、应用与未来展望

一、什么是zhaosf?

二、zhaosf的原理及实现方法
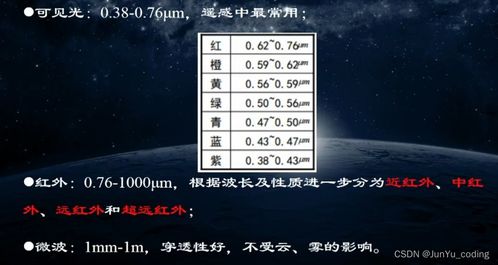
zhaosf的核心思想是利用已标记的数据,学习从原始特征到语义特征的映射,然后将这种映射应用于未标记的数据。通过插值的方式,模型能够推断出新类别的语义特征,从而实现零样本学习。
zhaosf的实现通常包括以下步骤:
1. 对已标记数据进行训练,学习特征表示和分类器。
2. 利用分类器对已标记数据计算语义特征。
3. 使用插值方法,根据已知类别的语义特征预测新类别的语义特征。
4. 使用预测的语义特征对新数据进行分类。
三、zhaosf的应用场景和优势
zhaosf在许多领域都有潜在的应用价值,尤其是那些类别分布不断变化,训练数据与测试数据类别不重叠的场景。例如,对于新兴疾病的预测,由于历史数据中可能没有相应的病例,zhaosf就可以利用已有的病例特征,推断出新疾病的特征表示,从而实现预测。
zhaosf的优势在于它不需要大量的训练数据,只需少量的已标记数据即可进行模型训练。此外,由于它能够识别从未见过的类别,因此在面对新的挑战时具有更强的适应能力。
四、zhaosf的局限性和挑战

尽管zhaosf具有许多优点,但它也存在一些局限性和挑战。首先,zhaosf的性能高度依赖于已标记数据的数量和质量。如果已标记数据不足以覆盖所有类别的语义空间,那么模型对新类别的预测可能会出现偏差。其次,zhaosf需要找到一种有效的插值方法,以准确地预测新类别的语义特征。这可能需要大量的实验和调整。最后,由于zhaosf需要预测新类别的语义特征,因此它可能无法充分利用训练数据中的所有信息。
五、zhaosf的发展趋势和未来展望
随着机器学习技术的不断发展,zhaosf也在不断进步和完善。未来的研究方向可能包括:
1. 改进插值方法:寻找更有效的插值方法,以提高对新类别的预测精度。
2. 增强模型泛化能力:通过改进模型结构或使用更先进的技术,使模型能够更好地适应不同的数据分布。
3. 结合其他技术:将zhaosf与其他机器学习技术(如迁移学习、深度学习等)相结合,以提高模型的性能。
总的来说,zhaosf作为一种零样本学习方法,已经在许多领域展现出其独特的优势和应用潜力。尽管还存在一些局限性和挑战,但随着技术的不断进步和完善,相信zhaosf在未来会有更广泛的应用和更好的性能表现。
5sy版权声明:以上内容作者已申请原创保护,未经允许不得转载,侵权必究!授权事宜、对本内容有异议或投诉,敬请联系网站管理员,我们将尽快回复您,谢谢合作!





